GaussDB理论考试内容
Gauss数据库部署
云数据库简介
云数据库是通过云平台构建和访问的数据库服务。它具有许多与传统数据库相同的功能,兼具了云计算的的灵活性。用户 可以在云基础架构上安装软件以使用数据库。
主要功能:
提供通过云平台构建和访问的数据库服务
支持企业用户托管数据库,无需购买专用硬件
可以由用户管理或由供应商以即服务方式提供并进行管理
可以支持 SQL 或 NoSQL 数据库
可以通过 Web 界面或供应商提供的 API 进行访问
云数据库优势:
易于访问
不需要关系底层服务器和系统等的部署与运维,开箱即用
可扩展性
灾难恢复
低成本
多租户模式,用户之间共享资源且 只用按需付费,节省了成本
高可用
高水平的容错能力,一个节点崩溃其他节点也能继续工作
动态可扩展
具有无限可扩展性,可以满足不断增加的数据存储需求。
大规模并行处理
并行处理能力强,面对海量数据,几乎可以做到实时的响应。
云数据库的劣势
数据质量
云数据库在大数据环境下,很容易产生脏数据,影响事务一致性
数据迁移
将大量、复杂的企业内部数据库数据迁移上云存在困难
数据融合
本地数据和云数据长期并存,需要有效的融合机制,统一管理。
性能优化
云环境为动态负载均衡、资源分配管理提出了新的要求
规范标准
各大厂商独立发展云数据库,在查询语言、语言模型和安全等方面缺乏统一的标准
GaussDB介绍
GaussDB是华为基于openGauss自研生态推出的企业级分布式关系型数据库。该产品具备企业级 复杂事务混合负载能力,同时支持分布式事务强一致,同城跨AZ部署,数据0丢失,支持1000+的 计算节点扩展能力,4PB海量存储。同时拥有云上高可用,高可靠,高安全,弹性伸缩,一键部 署,快速备份恢复,监控告警等关键能力,能为企业提供功能全面,稳定可靠,扩展性强,性能 优越的企业级数据库服务。
优点:
高安全
健全的工具与服务化能力
全栈自研
开源生态
灵活的部署状态
主备部署
1+1或1+2主备,基于数据库日志复制的热备,单机性能可满足需求的情况下,提供高可用
全分布式
分布式高扩展:数据按照shard划分,读写负载准线性扩展,满足大规模业务场景
分布式高可用:支持两地三中心高可用部署
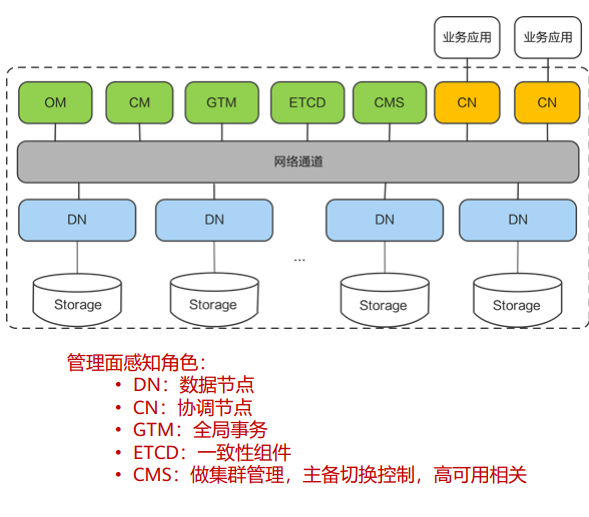
名称 | 描述 |
|---|---|
OM | 运维管理模块(Operation Manager)。提供集群日常运维、 配置管理的管理接口、工具。 |
CM | 集群管理模块(Cluster Manager)。管理和监控分布式系 统中各个功能单元和物理资源的运行情况,确保整个系统 的稳定运行。 |
GTM | 全局事务管理器(Global Transaction Manager),负责生 成和维护全局事务ID、事务快照、时间戳、sequence信息 等全局唯一的信息。 |
CN | 协调节点(Coordinator Node)。负责接收来自应用的访问 请求,并向客户端返回执行结果;负责分解任务,并调度 任务分片在各DN上并行执行。 |
DN | 数据节点(Data Node)。负责存储业务数据(支持行存、 列存、混合存储)、执行数据查询任务以及向CN返回执 行结果。 |
ETCD | 分布式键值存储系统(Editable Text Configuration Daemon)。用于共享配置和服务发现(服务注册和查找)。 |
Storage | 服务器的存储资源,持久化存储数据。 |
高性能-全并行分布式执行过程
业务应用下发SQL给Coordinator ,SQL可以包含对数据的增(insert)、删(delete/drop)、改(update)、查 (select)。
Coordinator利用数据库的优化器生成执行计划,每个DN会按照执行计划的要求去处理数据。
因为数据是通过一致性Hash技术均匀分布在每个节点,因此DN在处理数据的过程中,可能需要从其他DN获取数据, GaussDB 提供了三种stream流(广播流、聚合流和重分布流)来降低数据在DN节点间的流动。
DN将结果集返回给Coordinate进行汇总。
Coordinator将汇总后的结果返回给业务应用。
华为云基础知识
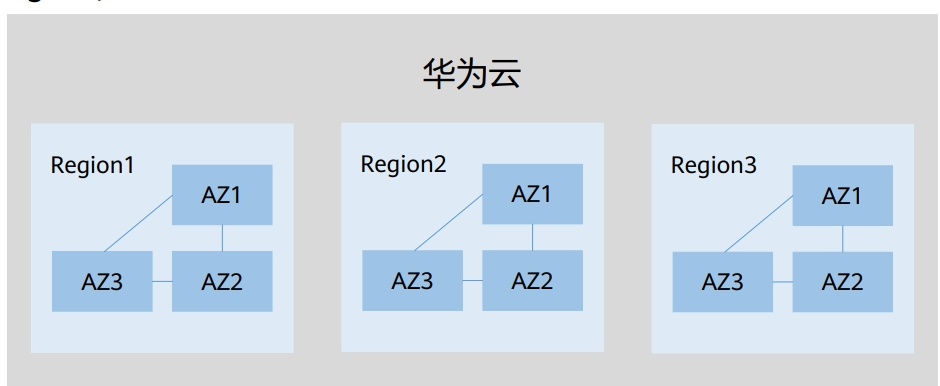
Region和AZ
区域(Region):从地理位置和网络时延维度划分,同一个Region内共享弹性计算、 块存储、对象存储、VPC网络、弹性公网IP、镜像等公共服务。
可用区(AZ,Availability Zone):一个AZ是一个或多个物理数据中心的集合,有 独立的风火水电,AZ内逻辑上再将计算、网络、存储等资源划分成多个集群。
一个Region中的多个AZ间通过高速光纤相连,以满足用户跨AZ构建高可用性系 统的需求。
Region分为通用Region和专属Region:
通用Region指面向公共租户提供通用云服务的Region;
专属Region指只承载同一类业务或只面向特定租户提供业务服务的专用Region。
网络相关概念
虚拟私有云VPC:GaussDB实例所在的虚拟专用网络,可以对不同业务进行网络隔离。按需创建 或选择所需的虚拟私有云。如果没有可选的虚拟私有云,GaussDB默认分配资源。
子网:通过子网提供与其他网络隔离的、可以独享的网络资源,以提高网络安全性。子网在可用 区内才会有效,创建GaussDB实例的子网默认开启DHCP功能,不可关闭。创建实例时GaussDB 会自动配置内网地址。
内网安全组:控制网络出/入及端口的访问,默认添加了GaussDB实例所属的内网安全组访问。内 网安全组限制实例的安全访问规则,加强GaussDB与其他服务间的安全访问。请确保所选取的内 网安全组允许客户端访问数据库实例。如果没有可选的内网安全组,GaussDB默认分配内网安全 组资源。
VPC简介
虚拟私有云(Virtual Private Cloud, 以下简称VPC),为云服务器、云容器、云 数据库等资源构建隔离的、用户自主配置和管理的虚拟网络环境,提升用户云上 资源的安全性,简化用户的网络部署。
在VPC中可以定义安全组、VPN、IP地址段、带宽等网络特性。用户可以通过VPC 方便地管理、配置内部网络,进行安全、快捷的网络变更。同时,用户可以自定 义安全组内与组间弹性云服务器的访问规则,加强弹性云服务器的安全保护。
VPC使用网络虚拟化技术,通过链路冗余、分布式网关集群、多AZ部署等多种技 术,保障网络的安全、稳定、高可用。
VPC组成部分
每个虚拟私有云VPC由一个私网网段、路由表和至少一个子网组成。
私网网段:用户在创建虚拟私有云VPC时,需要指定虚拟私有云VPC使用的私网网段。当前虚 拟私有云VPC支持的网段有10.0.0.0/824、172.16.0.0/1224和192.168.0.0/16~24。
路由表:在创建虚拟私有云VPC时,系统会自动生成默认路由表,默认路由表的作用是保证了 同一个虚拟私有云VPC下的所有子网互通。当默认路由表中的路由策略无法满足应用(比如未 绑定弹性公网IP的云服务器需要访问外网)时,您可以通过创建自定义路由表来解决。
安全组
安全组是一个逻辑上的分组,为具有相同安全保护需求并相互信任的云服务器提 供访问策略。安全组创建后,用户可以在安全组中定义各种访问规则,当云服务 器加入该安全组后,即受到这些访问规则的保护。
也可以根据需要创建自定义的安全组,或使用默认安全组,系统会为每个用户默 认创建一个默认安全组,默认安全组的规则是在出方向上的数据报文全部放行, 入方向访问受限,安全组内的云服务器无需添加规则即可互相访问。
安全组规则:安全组创建后,您可以在安全组中设置出方向、入方向规则,这些规则会对安全组内部的云服 务器出入方向网络流量进行访问控制,当云服务器加入该安全组后,即受到这些访问规则的保护。
EIP
弹性公网IP(Elastic IP,简称EIP)提 供独立的公网IP资源,包括公网IP地址 与公网出口带宽服务。可以与弹性云 服务器、裸金属服务器、虚拟IP、弹性 负载均衡、NAT网关等资源灵活地绑 定及解绑。
一个弹性公网IP只能绑定一个云资源使 用。
OBS对象存储服务
对象存储服务(Object Storage Service, OBS)是一个基于对象的海量存储服务, 为客户提供海量、安全、高可靠、低成本的数据存储能力。
OBS系统和单个桶都没有总数据容量和对象/文件数量的限制,为用户提供了超大 存储容量的能力,适合存放任意类型的文件,适合普通用户、网站、企业和开发 者使用。OBS是一项面向Internet访问的服务,提供了基于HTTP/HTTPS协议的 Web服务接口,用户可以随时随地连接到Internet的电脑上,通过OBS管理控制 台或各种OBS工具访问和管理存储在OBS中的数据。此外,OBS支持SDK和OBS API接口,可使用户方便管理自己存储在OBS上的数据,以及开发多种类型的上层 业务应用。
对象存储服务OBS的基本组成是桶和对象。
桶是OBS中存储对象的容器,每个桶都有自己的存储类别、访问权限、 所属区域等属性,用户在互联网上通过桶的访问域名来定位桶。
对象是OBS中数据存储的基本单位,一个对象实际是一个文件的数据 与其相关属性信息的集合体,包括Key、Metadata、Data三部分。
OBS对象
Key值:键值,即对象的名称,为经过UTF-8编码的长度大于0且不超 过1024的字符序列。一个桶里的每个对象必须拥有唯一的对象键值。
Metadata:元数据,即对象的描述信息,包括系统元数据和用户元数 据,这些元数据以键值对(Key-Value)的形式被上传到OBS中。
系统元数据由OBS自动产生,在处理对象数据时使用,包括Date,Contentlength,Last-modify,Content-MD5等。
用户元数据由用户在上传对象时指定,是用户自定义的对象描述信息。
Data:数据,即文件的数据内容。
GaussDB数据库开发环境
数据库驱动管理
数据库驱动是应用程序和数据库存储之间的一种接口,数据库厂商为了某一种开发语言环境(比如 Java,C)能够实现数据库调用而开发的类似翻译员功能的程序,将复杂的数据库操作与通信抽象 成为了当前开发语言的访问接口。因此,为了满足用户需求,GaussDB同时支持ODBC、JDBC、 Psycopg等数据库驱动。
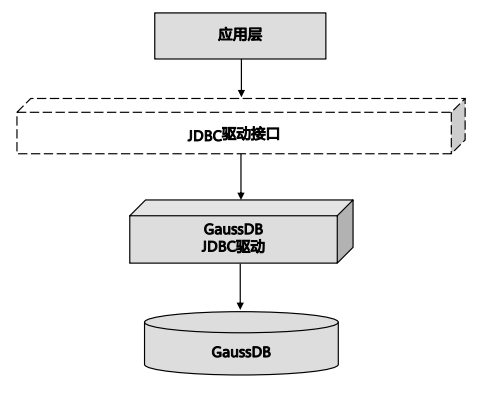
JDBC接口
JDBC(Java Database Connectivity,Java数据库连接)是一种用于执行SQL语句的Java API,可 以为多种关系数据库提供统一访问接口,应用程序可基于它操作数据。 GaussDB 提供了对JDBC 4.0特性的支持,需要使用JDK1.8版本编译程序代码,不支持JDBC桥接ODBC方式。
JDBC提供了三个方法,用于创建数据库连接。
DriverManager.getConnection(String url)
DriverManager.getConnection(String url, Properties info)
DriverManager.getConnection(String url, String user, String password)
ODBC接口
ODBC(Open Database Connectivity,开放数据库互连)是由Microsoft公司基于X/OPEN CLI提出的用于访问数据库的 应用程序编程接口。应用程序通过ODBC提供的API与数据库进行交互,增强了应用程序的可移植性、扩展性和可维护性。
常用接口
SQLConnect:在驱动程序和数据源之间建立连接。连接上数据源之 后,可以通过连接句柄访问到所有有关连接数据源的信息,包括程序 运行状态、事务处理状态和错误信息。
SQLExecute:如果语句中存在参数标记的话,SQLExecute函数使用参数标记参数的当前值,执 行一条准备好的SQL语句。
SQLFetch:从结果集中取下一个行集的数据,并返回所有被绑定列的数据。
SQLGetData:SQLGetData返回结果集中某一列的数据。可以多次调用它来部分地检索不定长度 的数据。
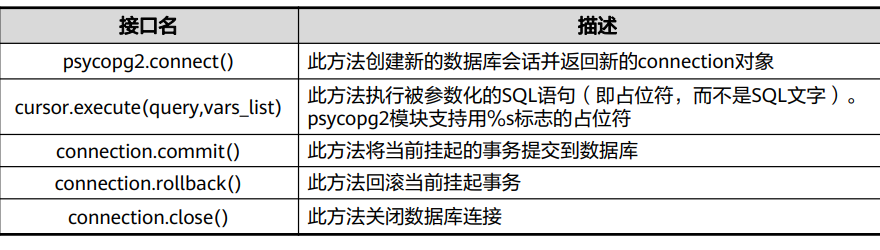
Psycopg接口
Psycopg是Python语言的GaussDB数据库接口。它的主要优势在于完 全支持Python DB API 2.0,以及安全的多线程支持。 它适用于随时 创建、销毁大量游标的和产生大量并发INSERT、UPDATE操作的多线 程数据库应用。
Psycopg使用它们的类型将Python变量转换为SQL值:Python类型确 定用于将对象转换为适合GaussDB的字符串表示形式的函数。
数据库客户端
客户端工具的存在主要是为了让用户更加便捷地连接数据库,对数据库进行各种操作和调试。
gsql介绍: GaussDB提供在命令行运行的交互式数据库连接工具,运行在Linux操作系统。
DAS介绍: 华为云数据管理服务(Data Admin Service,简称DAS)这款可视化的专业数据库管理工具,可获得执行SQL、高级 数据库管理、智能化运维等功能,做到易用、安全、智能的管理数据库。
第三方客户端Dbeaver工具介绍:
DBeaver是一个通用的数据库管理工具和 SQL 客户端,支持 MySQL、PostgreSQL、Oracle、DB2、MSSQL以及其他 兼容 JDBC 的数据库,提供一个图形界面用来查看数据库结构、执行SQL查询和脚本,浏览和导出数据、修改数据库 结构等。配置驱动后,可支持连接GaussDB集群中的数据库、管理数据库和数据库对象,编辑、运行、调试SQL脚本, 查看执行计划等。
gsql的使用方法
gsql可以直接将查询语句发给数据库执行,并返回执行结果:
postgres=# SELECT datname FROM pg_database;
datname
-----------
template1
template0
postgres
(3 rows)gsql工具还提供一些比较实用的元命令,用来快速与数据库交互。可以使用\l快速查询实例中的数据库:
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+-----------+---------+-------+-------------------
postgres | omm | SQL_ASCII | C | C |
template0 | omm | SQL_ASCII | C | C | =c/omm +
| | | | | omm=CTc/omm
template1 | omm | SQL_ASCII | C | C | =c/omm +
| | | | | omm=CTc/omm
(3 rows使用“\?”来查看使用说明
Column:字段名;
Type:字段类型;
Modifiers:约束信息;
postgres=# \d pg_database;
Table "pg_catalog.pg_database"
Column | Type | Modifiers
------------------+-----------+-----------
datname | name | not null
datdba | oid | not null
encoding | integer | not null
datcollate | name | not null
datctype | name | not null
datistemplate | boolean | not null
datallowconn | boolean | not null
datconnlimit | integer | not null
datlastsysoid | oid | not null
datfrozenxid | xid32 | not null
dattablespace | oid | not null
datcompatibility | name | not null
datacl | aclitem[] |
datfrozenxid64 | xid |所谓元命令就是在gsql里输入的任何以不带引号的反斜杠开头的命令。
常用命令
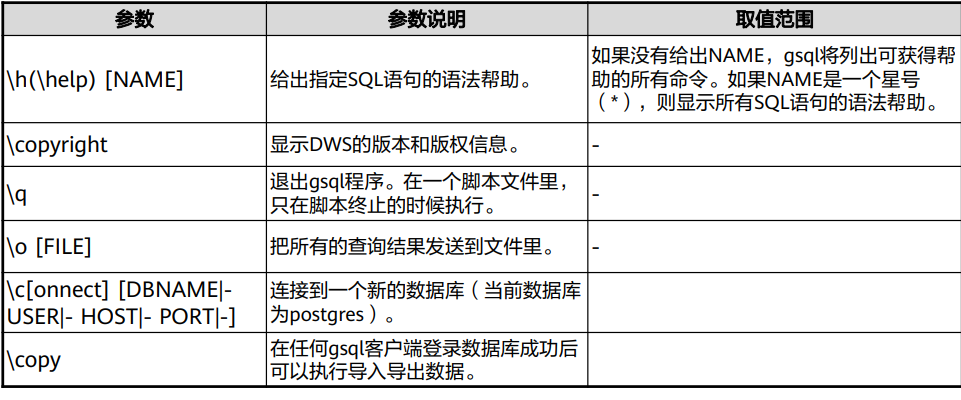
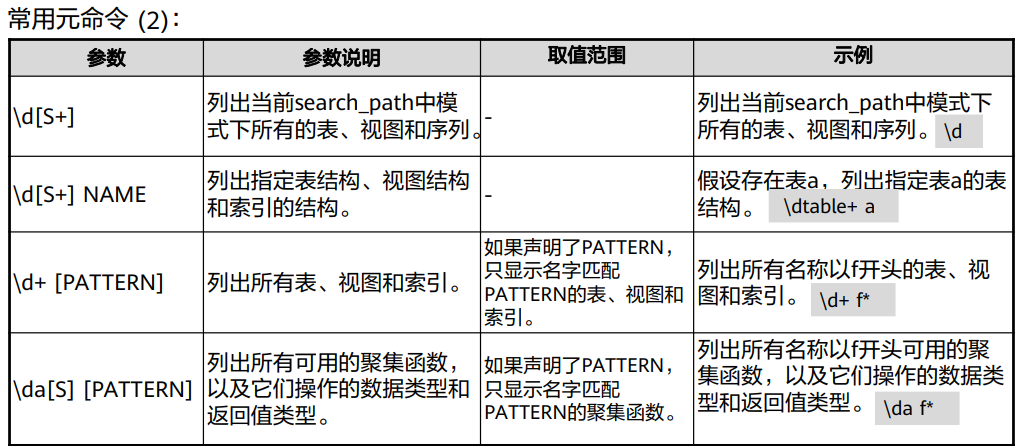
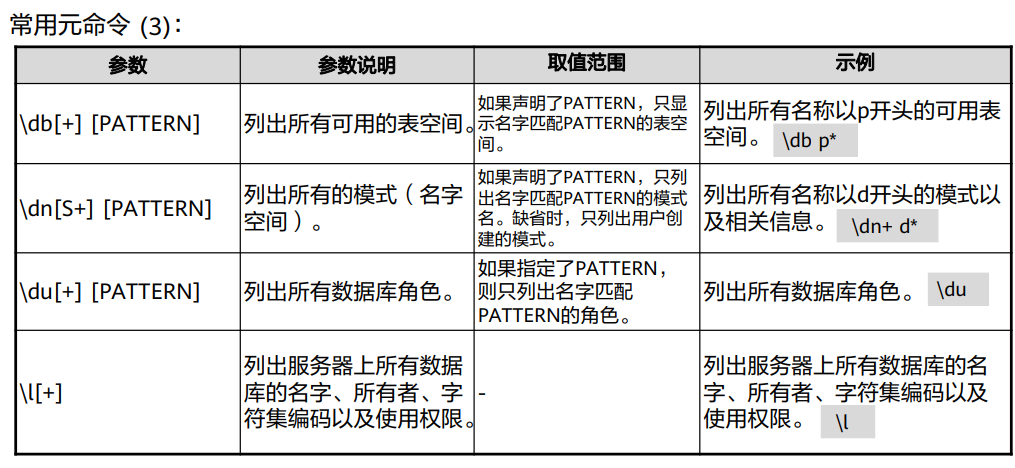
GaussDB数据库SQL及常规操作
数据类型
数值类型:数值类型又可以分成精确数值类型和近似数值类型,如int、bigint、float等。
字符类型:主要可分为定长字符类型和变长字符类型如char(n)、varchar(n)。
日期类型:主要包括日期和时间类型,如DATE和TIMESTAMP。
其他类型:如二进制类型、布尔类型等。
数值类型
整型类型
TINYINT
微整数,占用1字节,别名为INT1
取值范围 0-255
SMALLINT
小范围整数,占用2字节,别名为INT2
取值范围:-32768~+32767
INTEGER/BINARY_INTEGER
常用整数,占4字节,别名为INT4
BIGINT
大范围整数,占用8字节,别名为INT8
取值范围:-9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807
任意精度型
NUMERIC[(p[,s])]/DECIMAL[(p[,s])]:
用户声明精度。每四位占两个字节,然后在整个数据加上八个字节的额外开销
p为总位数,s为小数位数。精度p取值范围为[1,1000],标度s取值范围为[0,p]
取值范围:未指定精度的情况下,小数点前最大131,072位,小数点后最大16,383位。
NUMBER[(p[,s])]:
NUMERIC[(p[,s])]的别名
单精度浮点数
REAL/FLOAT4
双精度浮点数
FLOAT8/DOUBLE PRECISION/BINARY_DOUBLE
其他
FLOAT[(p)]/DEC[(p[,s])]/INTEGER[(p[,s])]
序列整型
SMALLSERIAL 2字节序列整形
SERIAL 4字节序列整形
BIGSERIAL 8字节序列整形
定长字符串类型
说明:定长字符串,不足补空格。n是指字节长度,如果不带精度n,默认的为1
存储空间最大为10MB
CAHR(n)
CHARACTER(n)
NCHAR(n)
变长字符串类型
CLOB/TEXT
存储文本大对象
最大为1GB-8203字节
VARCHAR(n)
存储变长字符串,n最大为10M
对应的关键字为VARCHAR/VARCHAR2/NVARCHAR2/CHARACTER VARYING。
日期类型
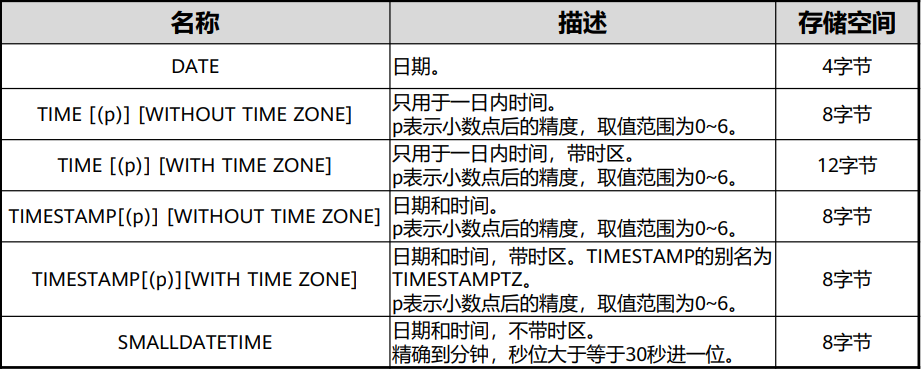

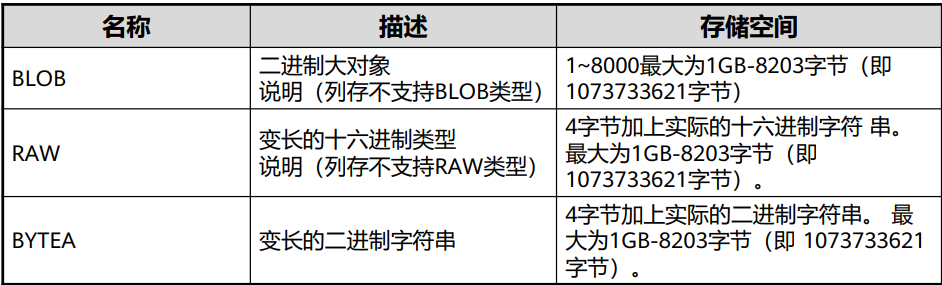
二进制类型
常用数据库对象
数据库对象是数据库的组成部分,数据库对象主要包含:表,索引,视图,存储过程,触发器,用户,函数等。
表
表是数据库中的一种特殊数据结构,用于存储数据对象以及对象之间的关系,由行和列组成的。
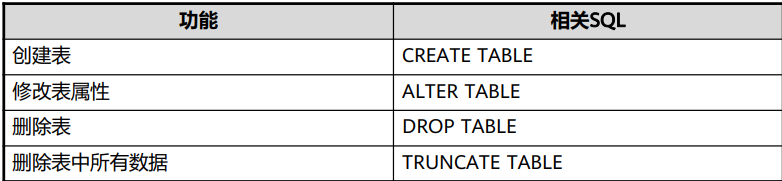
DROP TABLE会强制删除指定的表,删除表后,依赖该表的索引会被删除,而使用到该表的函数和存储过程将无法执 行。删除分区表,会同时删除分区表中的所有分区。
只有表的所有者或者被授予了表的DROP权限的用户才能执行DROP TABLE,系统管理员拥有该权限。
索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
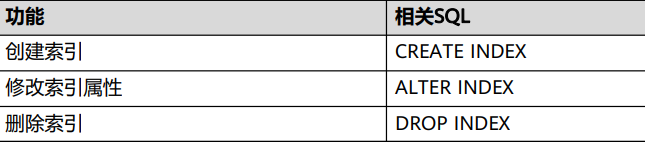
索引按照索引列数分为单列索引和多列索引,按照索引使用方法可以分为普通索引、唯一索引、 函数索引、分区索引。

在指定的表上创建一个索引。索引可以用来提高数据库查询性能,但是不恰当的使用将导致性能下降。
注意:
索引自身也占用存储空间、消耗计算资源,创建过多的索引将对数据库性能造成负面影响。因此,仅在必要时创建索 引。
在分区表上创建唯一索引时,索引项中必须包含分布列和所有分区键
视图
视图是从一个或几个基本表中导出的虚表,可用于控制用户对数据访问,所涉及的SQL语句,如 下表所示。

视图与基本表不同,数据库中仅存放视图的定义,而不存放视图对应的数据,这些数据仍存放在 原来的基本表中。若基本表中的数据发生变化,从视图中查询出的数据也随之改变。从这个意义 上讲,视图就像一个窗口,透过它可以看到数据库中用户感兴趣的数据及变化。
存储过程
存储过程是一组为了完成特定的功能SQL语句的集合。一般用于报表统计、数据迁移等
触发器
触发器是一种特殊的存储过程,通过指定的事件触发执行。一般用于数据审计、数据备份等。
函数
函数是对一些业务逻辑的封装,以完成特定的功能。函数执行完成后会返回执行结果。
函数与操作符
系统函数是对一些业务逻辑的封装,以完成特定的功能。系统函数可以有参数,也可以没有参数。 系统函数执行完成后会返回执行结果。
分类
数值计算函数
字符处理函数
时间日期函数
间隔函数
类型转换函数
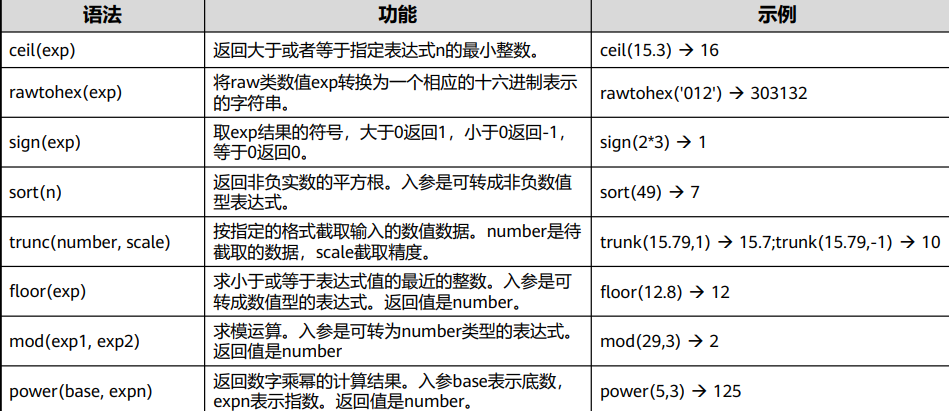
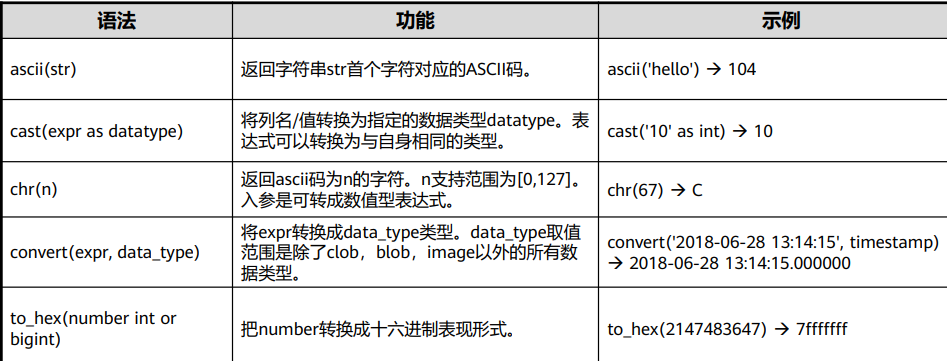
数值计算函数
abs(exp),cos(exp),sin(exp),acos(exp),asin(exp):返回表达式的绝对值,余弦值,正弦值, 反余弦值和反正弦值。
abs(exp)的返回值类型与参数exp数据类型相同,其他的返回值为number。
asin和acos函数说明:入参exp是可转成数值型的表达式,取值范围为[-1,1]。
bitand(exp1,exp2),bitor(exp1,exp2),bitxor(exp1,exp2) :按位与,按位或,按位异或运算。
round(number[decimals]),将number类数值按照decimals指定的小数点前后截断
字符处理函数
concat(str[,…]),concat_ws(separator,str1,str2,…):拼接一个或多个字符串。第一个函数无分隔 符,第二个函数可以指定分隔符连接。
hextoraw(str):将一个十六进制构成的字符串转换为二进制。
replace(str,src,dst):字符串插入和字符串替换函数。
instr(str1,str2[,pos[,n]])):字符串查找函数。返回要查找的字符串在源字符串中的位置。返回在 string1中从int1位置开始匹配到第int2次string2的位置,第一个int表示开始匹配起始位置,第二 个int表示匹配的次数。
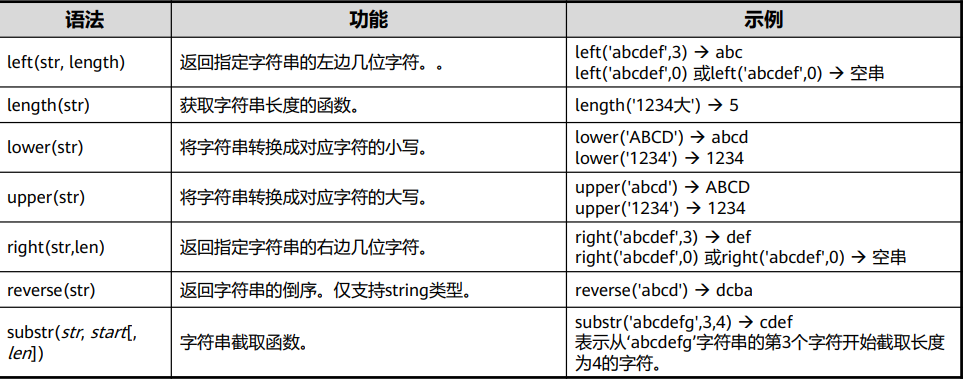
时间日期函数
add_months(date,n) :返回date加或减n个月后的值。
extract(field from datetime) :从指定的日期(datetime)中提取指定的时间字段(field),按 指定的格式截取输入的日期数据。
条件表达式函数
coalesce(expr1, expr2, ..., exprn):返回参数列表中第一个非NULL的参数值。
nullif(exp1,exp2):当且仅当expr1和expr2相等时,null才会返回null,否则它返回expr1
nvl(expr1,expr2):如果expr1为null则返回expr2,如果expr1非null则返回expr1
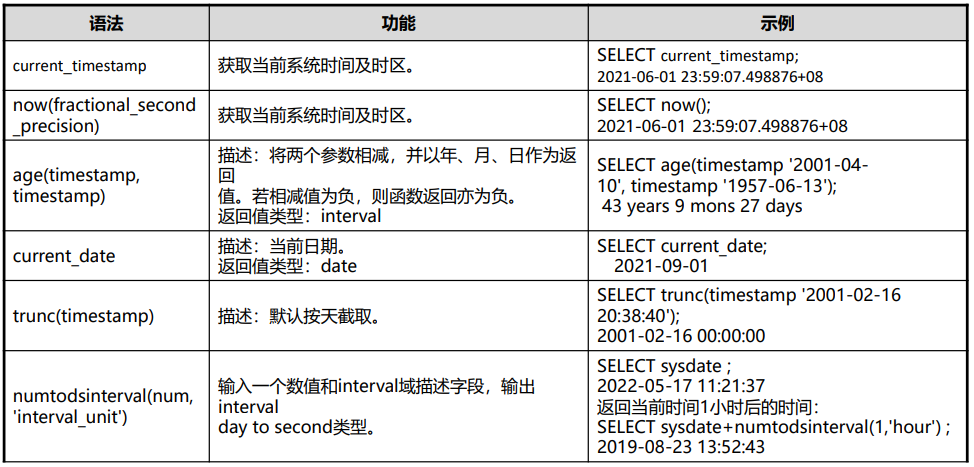
类型转换函数
to_char (datetime/interval [, fmt]),转换为字符串
to_clob(char/nchar/varchar/nvarchar/varchar2/nvarchar2/text/raw),转换为CLOB
to_date(text),to_number(text, text):将字符串类型的值转换为指定格式的数字。
数据查询
数据查询SQL顾名思义就是使用SQL语言对表中数据进行查询,主要介绍下常用 的几种查询方式
条件查询
join连接查询
子查询
结果集查询
聚集查询
数据排序、限制查询
外连接
内连接所指定的两个数据源处于平等的地位。而外连接不同,外连接以一个数据 源为基础,将另外一个数据源与之进行条件匹配。
内连接返回两个表中所有满足连接条件的数据记录。外连接不仅返回满足连接条件的记录,还将返回不满足连接条件的记录。
外连接又分为左外连接、右外连接和全外连接





数据操作
GaussDB数据库JDBC常用接口介绍
常用接口介绍
java.sql.Connection:用于与数据库建立连接(会话),在连接上下 文中执行SQL语句并返回。
java.sql.Driver:每个驱动程序类必须实现的接口。
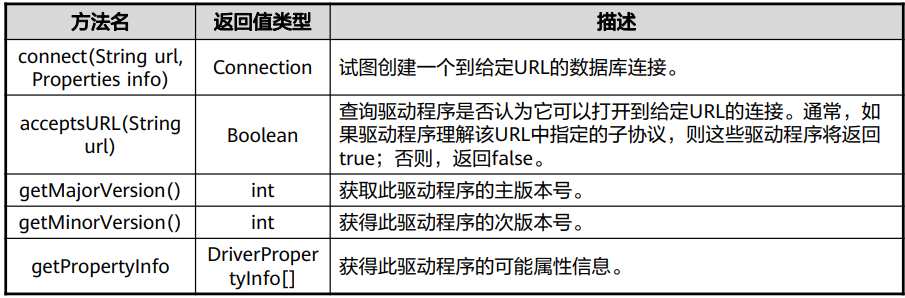
java.sql.ResultSet:表示数据库结果集的数据表,通常通过执行查询 数据库的语句生成。
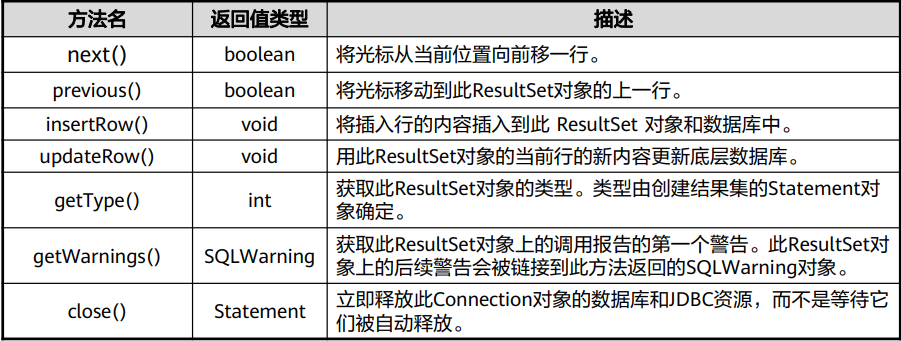
javax.sql.DataSource:用于提供到此DataSource对象所表示的物理 数据源的连接。
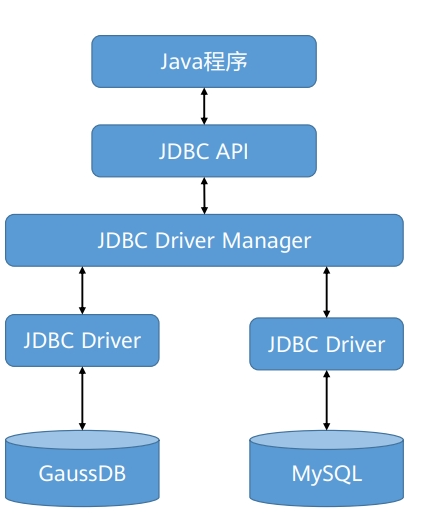
JDBC程序工作原理
JDBC体系结构由三层组成:
JDBC API:提供应用程序到JDBC管理器连接,提供程序调用的接口与类;
JDBC Driver Manager:对JDBC各类驱动进行管理载入;
JDBC Driver:负责连接不同的数据库
JDBC API主要功能为:
同数据库建立连接
◼ DriverManageer:使用通信子协议将来自java应用程序的连接请求与适当的数据库驱动程 序进行匹配,根据不同的数据库,管理JDBC驱动
◼ Connection:进行数据库连接,进行数据传输
Statement:执行SQL语句
处理结果:ResultSet:在使用Statement对象执行SQL查询后,这些对象保存从数据库检索的数据。
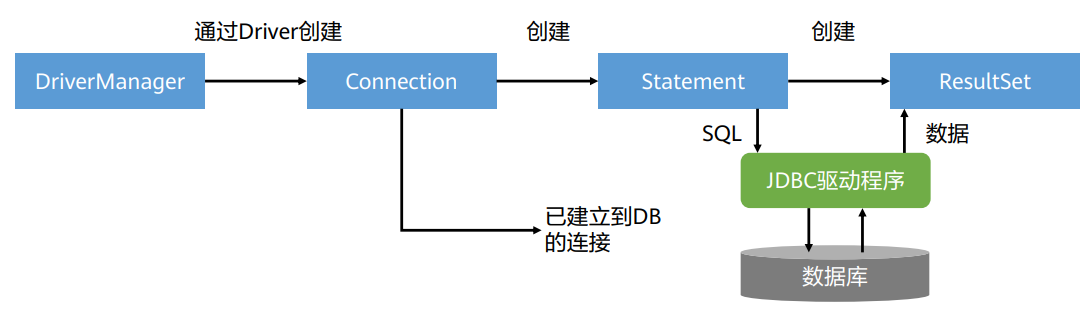
DriverManager类
DriverManager 类是用来管理数据库驱动的,在java.sql 包中大多数都是接口,DriverManager是为数不多的类之一。
DriverManager是非常常用的一个类,最主要的功能就是获得数据库的连接,它定义了三个方法,用于创建数据库连接。 差别在于参数的数量上。
DriverManager.getConnection(String url);
DriverManager.getConnection(String url, Properties info);
DriverManager.getConnection(String url, String user, String password);最常用
使用gsjdbc4.jar时,数据库URL(Uniform Resource Locator,统一资源定位符)连接描述符如下: jdbc:postgresql://host:port/database
使用gsjdbc200.jar时,数据库URL连接描述符如下: jdbc:gaussdb://host:port/database
Connection接口
Connection接口表示应用程序与数据库的连接对象,在连接上下文中执行 SQL 语句并返回结果。 每个Connection代表一个物理连接会话,想要访问数据库,必须先获得数据库连接。通过 Connection 对象,可以获得操作数据库的 Statement、PreparedStatement,CallableStatement 等对象。
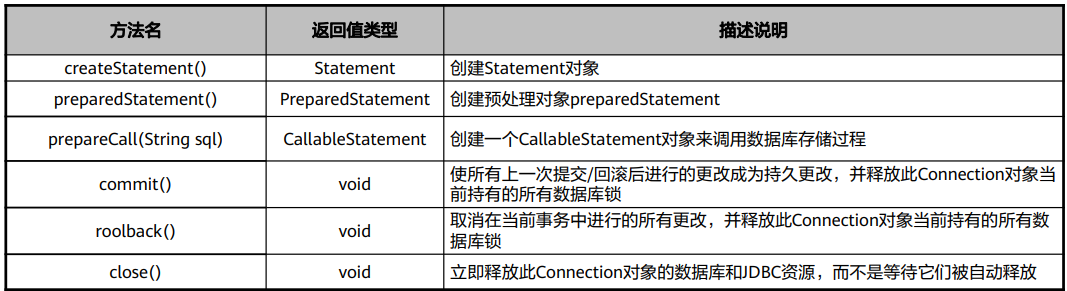
创建一个 Statement 对象来将 SQL 语句发送到数据库。不带参数的 SQL 语句通常使用 Statement 对象执 行。如果多次执行相同的 SQL 语句,使用 PreparedStatement 对象可能更有效。
使用返回的 Statement 对象创建的结果集在默认情况下类型为 TYPE_FORWARD_ONLY,并带有 CONCUR_READ_ONLY 并发级别。
Connection接口 - prepareStatement方法
创建一个 PreparedStatement 对象来将参数化的 SQL 语句发送到数据库。带有 IN 参数或不带有 IN 参数的 SQL 语句都可以被预编译并存储在 PreparedStatement 对象中,预编译语句是只编译和优化一次,可以有 效地使用此对象来多次执行该语句。由于已经预先编译好,后续使用会减少执行时间。因此,如果多次执行 一条语句,选择使用预编译语句。
Connection接口 - prepareCall方法
创建一个CallableStatement对象来调用数据库存储过程。CallableStatement对象提供了设置其IN和OUT参 数的方法,以及用来执行调用存储过程的方法。
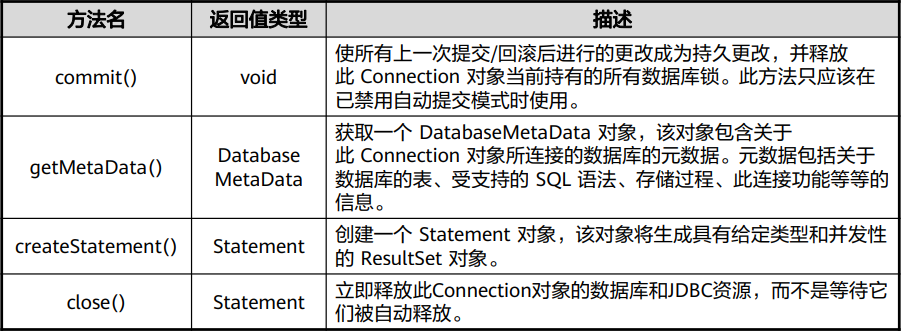
Connection接口 – 其他方法
commit方法
使所有上一次提交/回滚后进行的更改成为持久更改,并释放此Connection对象当前持有的所有数据库锁。此方法只应 该在已禁用自动提交模式时使用,与setAutoCommit方法使用相关。
rollback方法
取消在当前事务中进行的所有更改,并释放此 Connection 对象当前持有的所有数据库锁。此方法只应该在已禁用自 动提交模式时使用,与setAutoCommit方法使用相关。
close方法
立即释放此 Connection 对象的数据库和 JDBC 资源,而不是等待它们被自动释放。在已经关闭的 Connection 对象上 调用 close 方法无操作。
Statement接口
用于执行静态 SQL 语句并返回它所生成结果的对象。在默认情况下,同一时间每个 Statement 对象在只能打开一个 ResultSet 对象。因此,如果读取一个 ResultSet 对象与读取另一个交叉, 则这两个对象必须是由不同的 Statement 对象生成的。如果存在某个语句的打开的当前 ResultSet 对象,则 Statement 接口中的所有执行方法都会隐式关闭它。
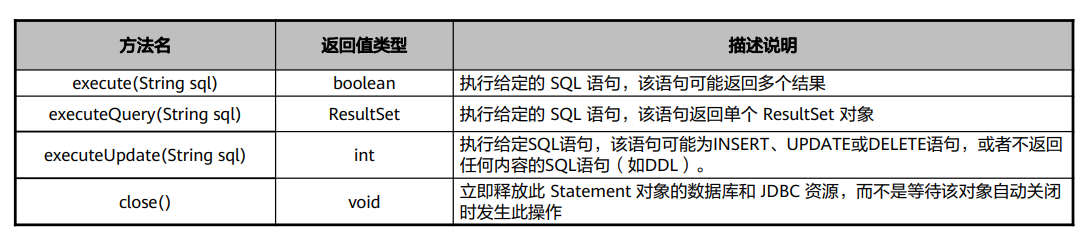
Statement接口 – execute方法
执行给定的 SQL 语句,该语句可能返回多个结果,execute 方法执行 SQL 语句并指示第一个结果的形式。 然后,必须使用方法getResultSet 或 getUpdateCount 来获取结果,使用 getMoreResults 来移动后续结果。
Statement接口 – executeQuery方法
执行给定的 SQL 语句,该语句返回单个 ResultSet 对象,该方法只能用于执行查询语句。
Statement接口 – executeUpdate方法
执行给定SQL语句,该方法用于执行DML语句,并返回受影响的行数,同时也可以用于执行DDL语句,执行 后返回0。
PreparedStatement接口
PreparedStatement接口表示预编译的 SQL 语句的对象,是Statement的子接口,它允许数据库 预编译SQL语句(这些SQL语句通常都带有参数),以后每次只改变SQL命令的参数,避免数据库 每次都需要编译SQL语句,因此性能更好。相对于Statement而言,使用PreparedStatement执行 SQL语句时,无需再传入SQL语句,只要为预编译的SQL语句传入参数值即可

CallableStatement接口
CallableStatement接口用于执行SQL存储过程的接口,它是PreparedStatement的子接口。
CallableStatement对象是通过调用Connection对象的prepareCall()方法创建的。prepareCall()方法有三种 形式,既支持创建使用默认类型的ResultSet的CallableStatement对象,也支持开发人员创建指定类型的 ResultSet的CallableStatement对象。这与创建Statement对象过程相似.
存储过程的运行是在数据库内部进行的,存储过程除了能查询并返回数据之外,存储过程还支持IN、OUT参 数。所以,这也使得CallableStatement接口的使用方法与PreparedStatement稍有不同。 CallableStatement接口主要有以下几种:

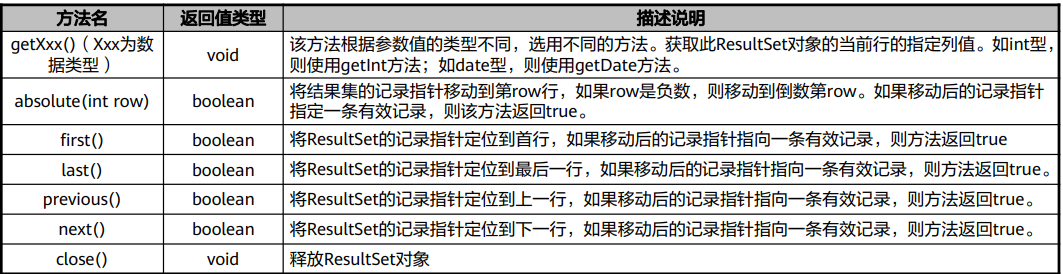
ResultSet接口
ResultSet接口为结果集对象,该对象包含访问查询结果的方法,通常通过执行查询数据库的语句 生成。
ResultSet接口类似于一个临时表,ResultSet实例具有指向当前数据行的指针,指针开始的位置在 第一条记录的前面,通过next()方法可以将指针向下移动;ResultSet可以通过列索引或列名获得 列数据。常用方法如下:

ResultSetMetaData接口
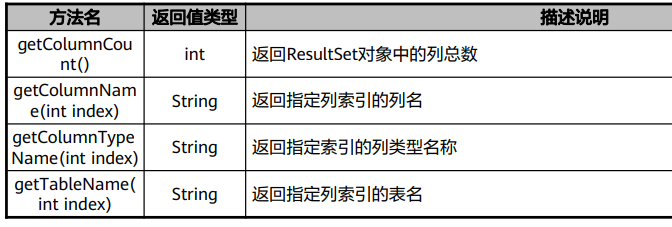
ResultSetMetaData接口用于收集ResultSet的所有元数据信息,例如列的类型和 属性,列数,列的名称,列的数据类型等。
ResultSetMetaData接口封装了描述ResultSet对象的数据,内部提供了大量的方 法来获取ResultSet的信息。
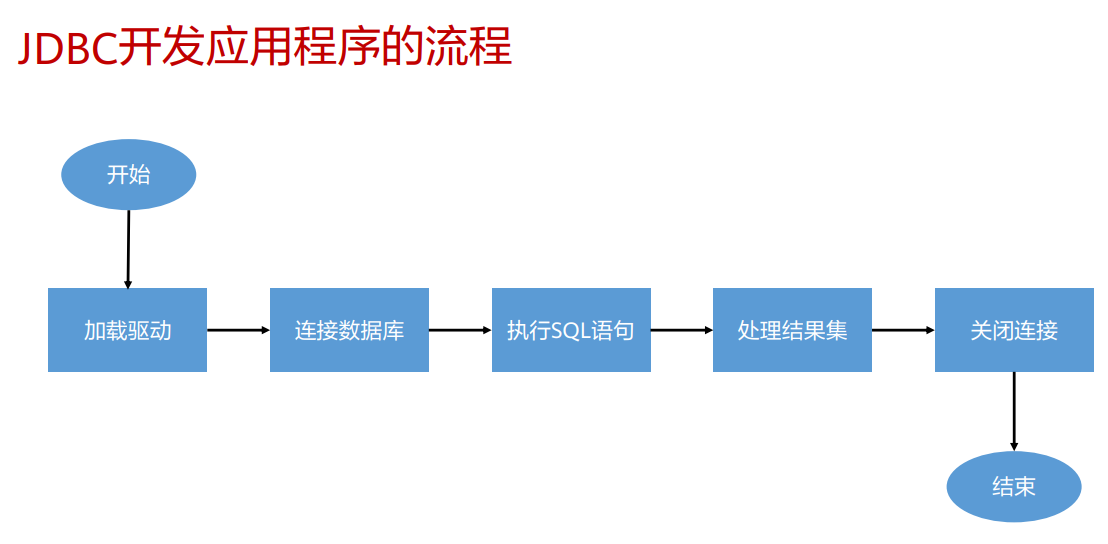
GaussDB数据库基础操作java编程
开发流程概述
从官网获取JDBC包,GaussDB提供的JDBC驱动包。包名为GaussDB-KernelVxxxRxxxCxx-操作系统版本号-64bit-Jdbc.t
解压后有两个JDBC的驱动jar包:
gsjdbc4.jar:与PostgreSQL保持兼容的驱动包,其中类名、类结构与PostgreSQL驱动完全一 致,曾经运行于PostgreSQL的应用程序可以直接移植到当前系统使用。
gsjdbc200.jar:如果同一JVM进程内需要同时访问PostgreSQL及GaussDB时,需使用此驱动包。
在创建数据库连接之前,需要加载数据库驱动类“org.postgresql.Driver”
基本操作
加载驱动
在创建数据库连接之前,需要先加载数据库驱动程序。
加载驱动有两种方法:
在代码中创建连接之前任意位置隐含装载:Class.forName("org.postgresql.Driver")
在JVM启动时参数传递:java -Djdbc.drivers=org.postgresql.Driver jdbctes
配置环境
客户端需配置JDK1.8版本,JDK是跨平台的,支持Windows/Linux等多种平台, 下面以Linux为例,介绍JDK配置流程:
获取JDBC驱动和JDK软件包,并将软件包上传至客户端处。
将安装路径添加至java_home/classpath/path环境变量中。
输入“java -version”,查看JDK版本,确认为JDK1.8版本。
输入“javac –version”,查看javac是否正常运行。
连接数据库

执行SQL
程序中,一般使用Statement接口和PreparedStatement接口执行SQL语句。
对于较为简单的create table建表语句与insert插入单条记录语句,使用了 Statement接口,应用程序通过该接口执行SQL语句来操作数据库的数据,执行 不用传递参数的语句;
PreparedStatement接口则主要执行较为复杂的语句,预编译语句是只编译和优 化一次,然后可以通过设置不同的参数值多次使用。实验中的update更新、 delete删除和批量插入操作,都使用了PreparedStatement接口
结果集
不同类型的结果集有各自的应用场景,应用程序需要根据实际情况选择相应的结 果集类型。在执行SQL语句过程中,都需要先创建相应的语句对象,而部分创建 语句对象的方法提供了设置结果集类型的功能。
创建一个Statement对象,该对象将生成具有给定类型和并发性的ResultSet对象。
createStatement(int resultSetType, int resultSetConcurrency)
创建一个PreparedStatement对象,该对象将生成具有给定类型和并发性的 ResultSet对象。 prepareStatement(String sql, int resultSetType, int resultSetConcurrency);
使用ResultSet接口方法处理结果集
ResultSet对象具有指向其当前数据行的指针。最初,指针被置于第一行之前。 next方法将指针移动到下一行;next方法在ResultSet对象没有下一行时,会返回 false,所以可以在while循环中使用它来迭代结果集。但对于可滚动的结果集, JDBC驱动程序提供更多的定位方法,使ResultSet指向特定的行。
Statement stmt =conn.createStatement();
ResultSet rs =stmr.executeQuery(“select * from test”);
while(rs.next()){
for (int i = 0; i < metaData.getColumnCount(); i++) {
System.out.print(rs.getString(i + 1) + "\t");
}
}关闭连接
在使用数据库连接完成相应的数据操作后,需要关闭数据库连接。
很多的数据库类如Connection、Statement和ResultSet都有close()方 法,在使用完对象后应把它们关闭。需要注意的是,Connection的关 闭将间接关闭所有与它关联的Statement,Statement的关闭间接关闭 了ResultSet。